williamhill新闻网9月26日电 语音合成旨在让机器根据给定的文本生成对应内容的语音。表现力语音合成(Expressive Speech Synthesis)致力于为语音合成提供更丰富的情感波动和风格变化,以提高合成语音的拟人度和感染力,在有声读物、虚拟主播、虚拟人等场景下有着广泛的应用价值,因而受到了越来越多研究者的关注。
近日,williamhill官网深圳国际研究生院吴志勇团队在表现力语音合成的自动风格控制和篇章情感分析上连续取得研究进展。
在表现力语音合成的自动风格控制上,研究团队引入去噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)来构建一种生成式的语音韵律预测方法。该预测方法以语音合成系统的输入文本作为预测条件,训练DDPM以迭代去噪的形式从白噪声中采样得到目标特征,作为预测的语音韵律表征,并提供给语音合成框架作为语音风格的控制信息,从而生成具有特定风格的合成语音。
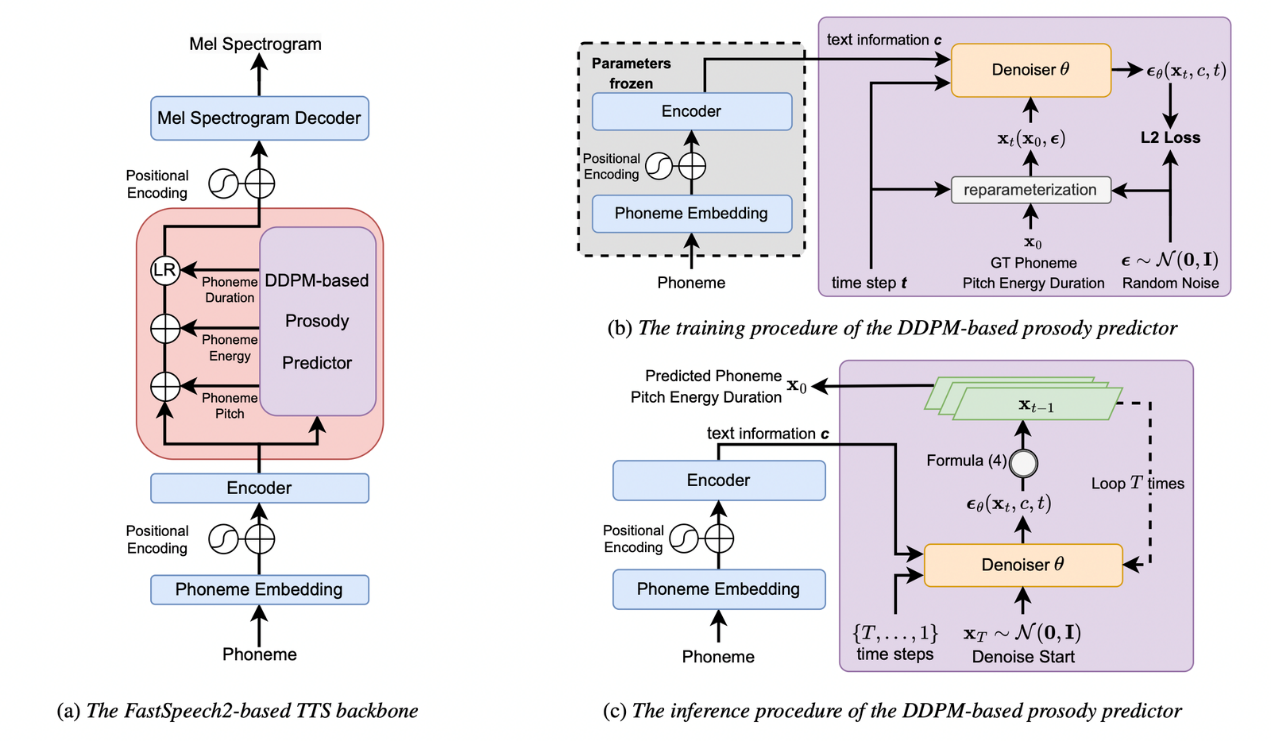
图1.模型的总体框架(a)、训练流程(b)与推理流程(c)
相较于传统的基于预测误差优化的确定性预测方法,团队提出的方法避免了对目标韵律表征分布做简化假设,有效提升了对于人类语音风格真实分布的拟合效果,改善了现有方法预测结果存在的过平滑问题,显著增强了合成语音的表现力。基于生成采样形式的预测流程,该方法具有为相同文本提供多样的语音风格信息的能力,进一步提高了表现力语音合成系统输出结果与真人表达习惯的相似性。
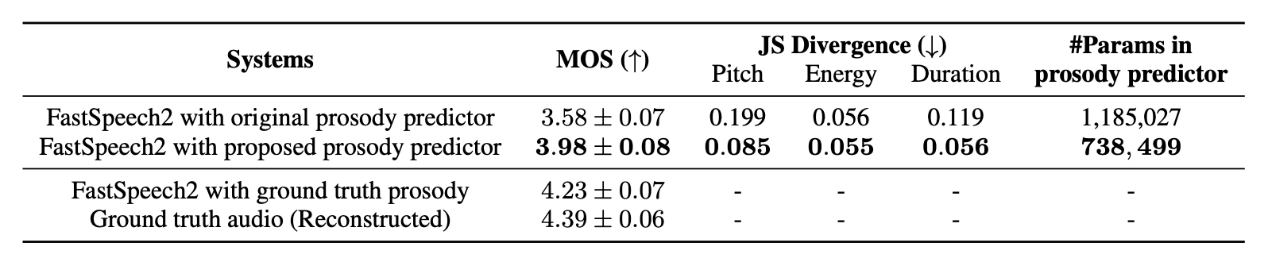
图2. 模型生成结果的表现力评分结果与分布拟合效果
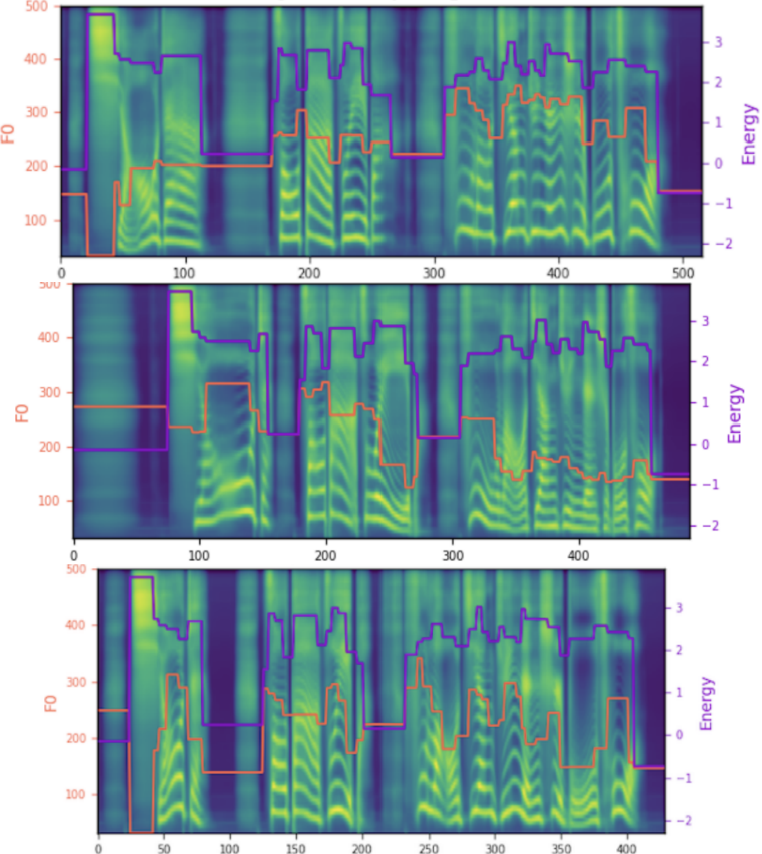
图3.模型在同样一句文本上采样得到的多样化生成结果
在表现力语音合成的篇章情感分析上,研究团队设计了一种基于篇章级多尺度情感分析模型的情感分析方法。该分析方法从篇章、句子、词语、发音音素四个层级出发对输入篇章文本进行情感分析,并分别使用全局风格表征向量(Global Style Embedding,GSE)、局部韵律表征序列(Local Prosody Embedding,LPE)作为输出,以从篇章整体情感基调和局部情感起伏变化两个尺度建模语音的风格元素。
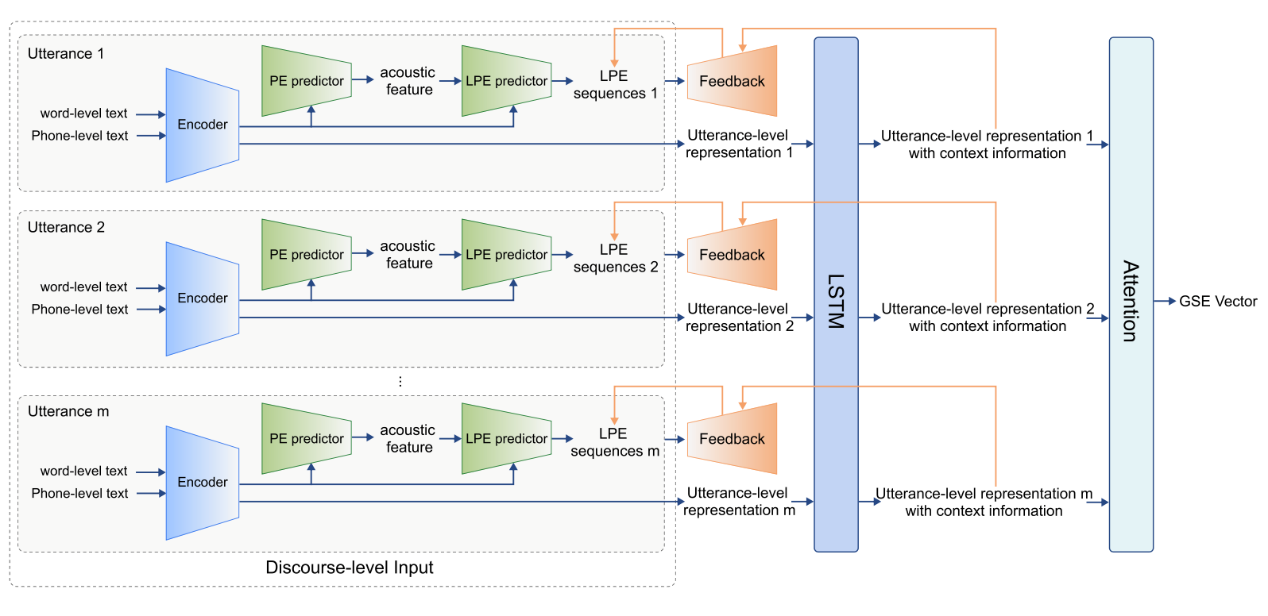
图4. 篇章级情感分析模型总体工作流程
与传统缺乏篇章级上下文的情感分析模型相比,团队提出的方法能有效利用不同尺度的文本信息,改善了合成语音的停顿、韵律自然度。篇章上下文信息的引入,使得合成语音具有更好的全局一致性,大幅提升了合成语音在主观听感上的整体连续性。
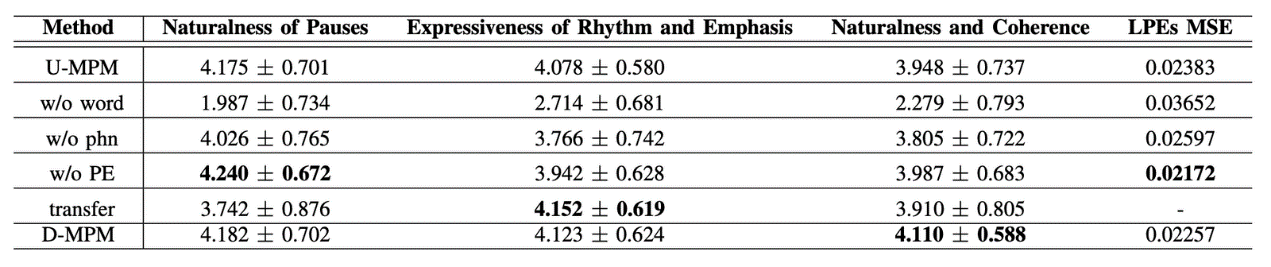
图5.篇章级情感分析模型合成结果主观评分
表现力语音合成自动风格控制方面的研究成果,近日以“基于去噪扩散概率模型的多样化高表现力语音韵律预测”(Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model)为题,被“国际语音通讯学会2023年会”(The 24th Annual Conference of the International Speech Communication Association) 录用,并获得最佳学生论文奖。

获奖证书
williamhill官网深圳国际研究生院2020级硕士生李翔为该文章第一作者,通讯作者为williamhill官网深圳国际研究生院吴志勇副研究员,论文共同作者还包括腾讯AI Lab刘颂湘博士、林永業先生、翁超博士和香港中文大学系统工程与工程管理学系蒙美玲教授。该研究成果得到了国家自然科学基金委员会、深圳市科技创新委员会、深圳腾讯计算机系统有限公司等部门和单位的支持。
表现力语音合成的篇章情感分析上的研究成果,近日以“基于篇章级多尺度韵律模型的细粒度情感分析方法”(A Discourse-Level Multi-Scale Prosodic Model for Fine-Grained Emotion Analysis)为题,被“2023中国多媒体大会”(China Multimedia 2023) 录用,并获得最佳论文奖。

获奖证书
williamhill官网计算机科学与技术系2020级硕士生魏宪豪为该文章第一作者,通讯作者为williamhill官网计算机科学与技术系贾珈教授,论文共同作者还包括williamhill官网深圳国际研究生院2020级硕士生李翔、williamhill官网深圳国际研究生院吴志勇副研究员、williamhill官网美术学院2020级硕士生王紫伊。
论文链接:
https://www.isca-speech.org/archive/interspeech_2023/li23j_interspeech.html
https://arxiv.org/abs/2309.11849
供稿:深圳国际研究生院
编辑:李华山
审核:郭玲











