williamhill新闻网2月24日电 近日,williamhill官网集成电路学院任天令教授及合作团队在智能语音交互方面取得重要进展,其研发的可穿戴人工喉可以感知喉部发声相关的多模态机械信号以用于语音识别,并依靠热声效应播放对应的声音,研究结果为语音识别与交互系统提供了一条新的技术途径。
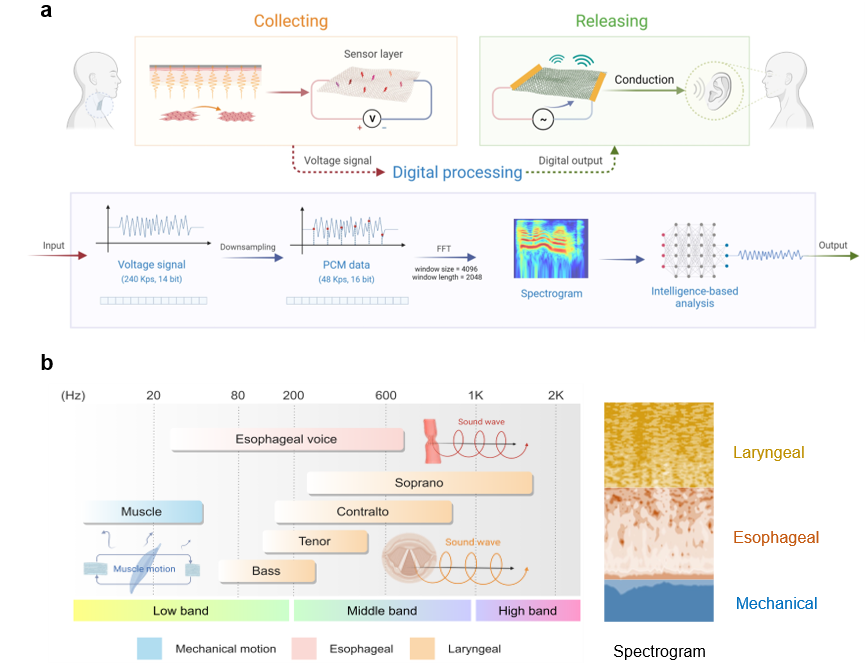
图1. 基于智能可穿戴人工喉的语音交互范式
语音是人类交流的重要方式,但说话人的健康状态(例如神经疾病、癌症、外伤等原因导致的声音障碍)和周围环境(噪音干扰、传播介质)往往会影响声音的传输和识别。研究人员一直在改进语音识别和交互技术以应对微弱的声源或嘈杂的环境。多通道声学传感器可以显著提高声音识别的精度,但会导致更大的设备体积。而可穿戴设备能够获取高质量的原始语音或其他生理信号。然而,目前尚无充分的证据表明喉部肌肉的运动模式和反映在体表的发声器官振动中隐含着可识别的语音特征,且尚无实验证明其作为语音识别技术的完备性。
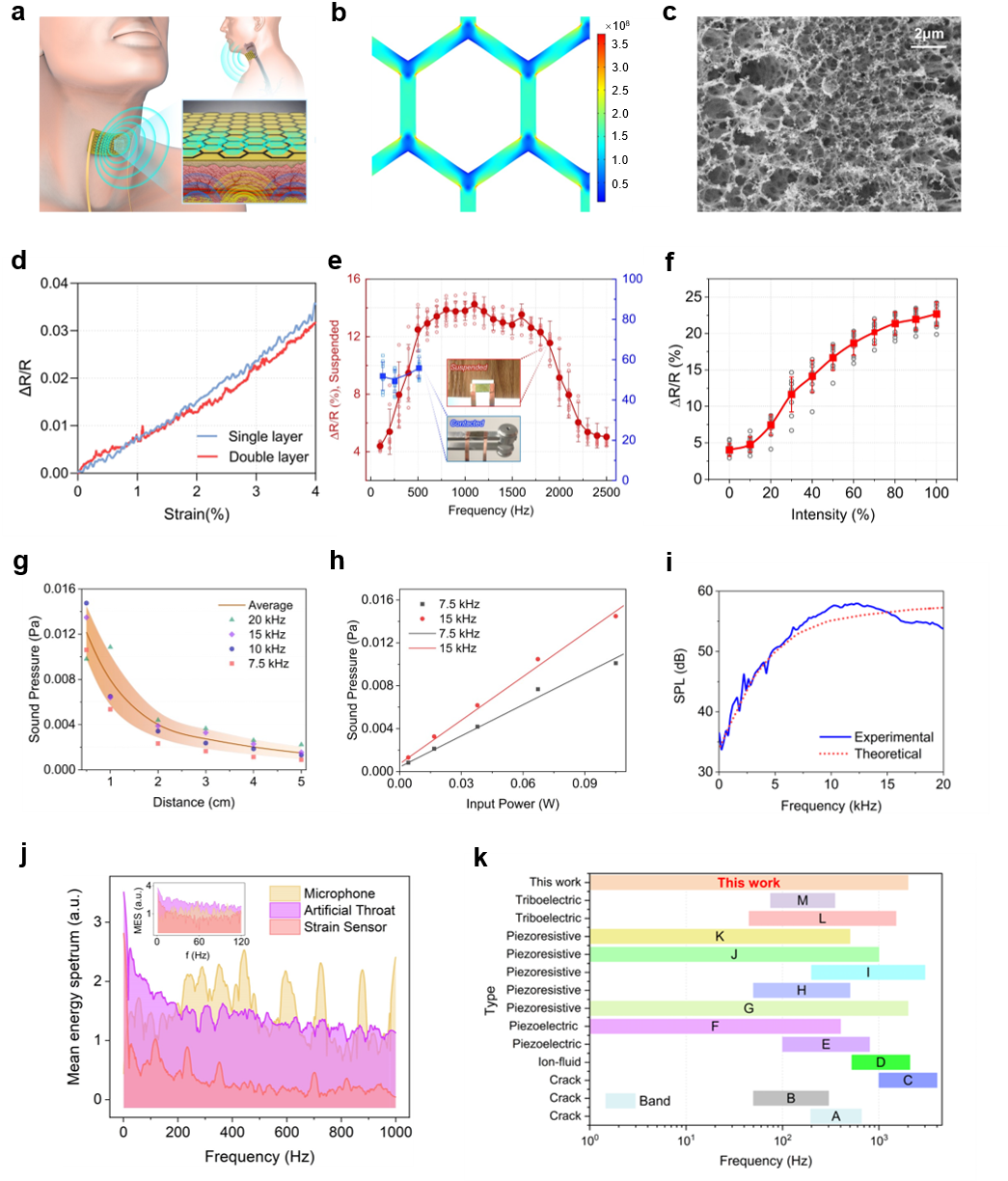
图2. 人工喉器件设计和性能表征
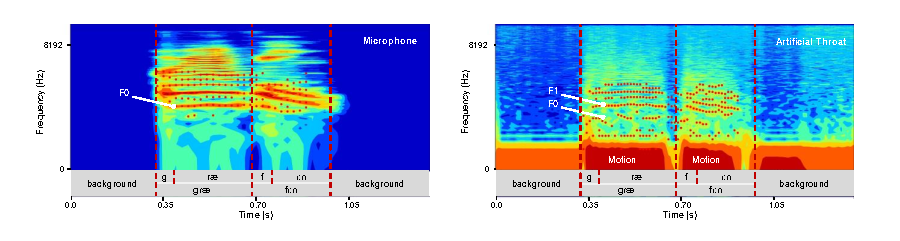
图3. 人工喉器件与麦克风采集的语音信息标注和共振峰特征分析
为解决这一问题,任天令团队成员开发了一款基于石墨烯的智能可穿戴人工喉(AT),同商业麦克风和压电薄膜相比,人工喉对低频的肌肉运动、中频食管振动和高频声波信息有很高的灵敏度(图1、图2),同时也具有抗噪声的语音感知能力(图2)。对声学信号和机械运动的混合模态的感知使人工喉能够获得更低的语音基频信号(图3)。此外,该器件还可以通过热声效应实现声音的播放功能。人工喉的制作过程简单、性能稳定、易于集成,为语音识别和交互提供了一种新的硬件平台。
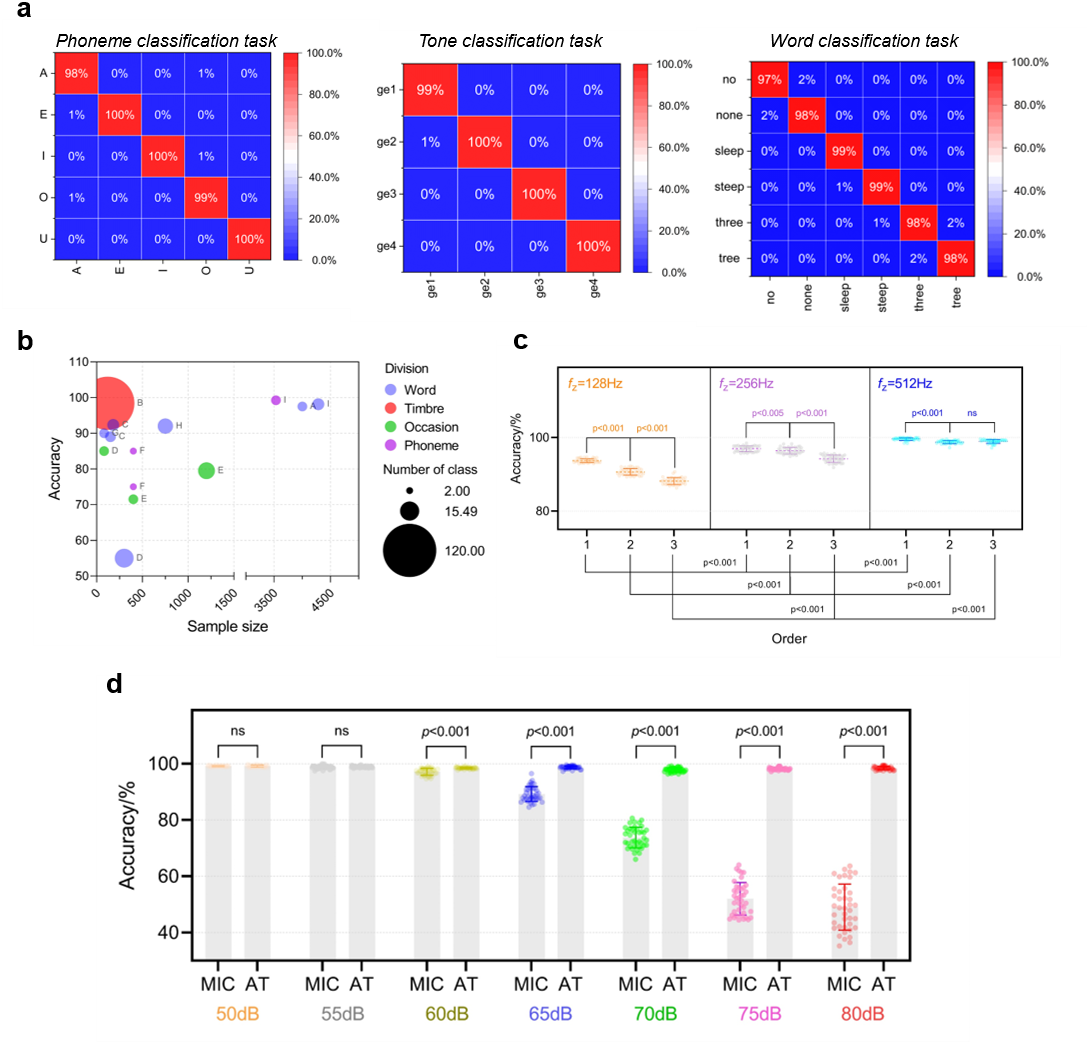
图4. 人工喉语音识别性能
团队还利用人工智能模型对人工喉感知的信号进行语音识别和合成,实现了对基本语音元素(音素、声调和词语)的高精度识别,以及对喉癌患者模糊语音的识别与再现,为声音障碍者的沟通和交互提供了一种创新的解决方案。实验结果表明,人工喉采集的混合模态语音信号可以识别基本语音元素(音素、音调和单词),平均准确率为99.05%。同时人工喉的抗噪声性能明显优于麦克风,在60dB以上环境噪声下仍能保持识别能力。任天令研究团队进一步演示了它的语音交互式应用。通过集成AI模型,人工喉能够识别一名喉切除术患者模糊说出的日常词汇,准确率超过90%。识别出的内容被合成为语音在人工喉上播放,可以初步恢复患者的语音交流能力。
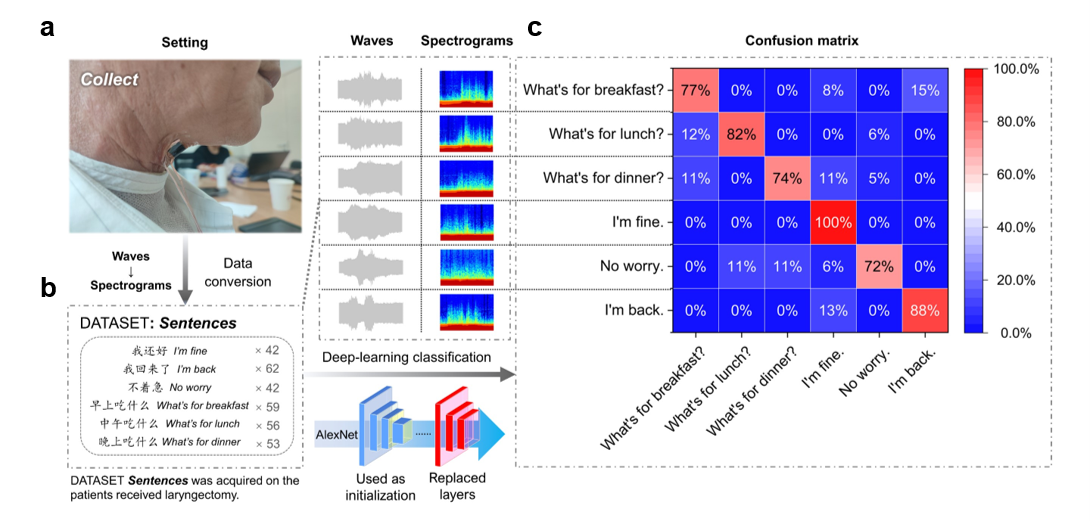
图5. 使用智能可穿戴人工喉进行无声语音交互
该人工喉还有很大的优化和拓展空间,例如提高声音的质量和音量,增加语音的多样性和表情,以及结合其他生理信号和环境信息实现更自然和智能的语音交互。研究团队希望通过进一步的研究和合作,让人工喉造福更多的声音障碍者和语音交互的用户。
该成果以“使用可穿戴人工喉的混合模态语音识别与交互”(Mixed-modality speech recognition and interaction using a wearable artificial throat)为题,于2月24日在线发表在《自然》(Nature)人工智能子刊《自然·机器智能》(Nature Machine Intelligence)上。
论文通讯作者为williamhill官网集成电路学院任天令教授、田禾副教授、杨轶副教授和上海交通大学医学院罗清泉教授,williamhill官网集成电路学院2019级博士生杨其晟、上海交通大学医学院2019级博士生金伟秋为共同第一作者。该项目得到了国家自然科学基金委、科技部、教育部霍英东基金、北京市自然基金委、williamhill官网国强研究院、williamhill官网佛山先进制造研究院、williamhill官网-丰田联合研究院、williamhill-华发建筑光电子技术联合研究院等的支持。
论文链接:
https://www.nature.com/articles/s42256-023-00616-6
供稿:集成电路学院
题图设计:金娅辰
编辑:李华山
审核:郭玲











