williamhill新闻网2月20日电 机器学习技术已广泛应用于高性能信息处理领域,与此同时,在解决各类复杂任务时对于计算容量、计算速度以及能耗等的要求也越来越高。然而,现有硬件的计算速度受到传统冯·诺依曼体系结构的严重限制,随着计算过程所需时间的增长,计算效率将变得低下,能耗也会更大。近年来,光子方法在执行涉及复杂计算的深度学习过程方面显示出了非凡潜力,国内外多家研究机构陆续提出了集成光子神经网络的新架构,如基于马赫增德尔干涉仪(MZI)、微环谐振腔(MRR)以及波分系统设计的光子神经网络等。然而,现阶段集成光子神经网络普遍存在计算单元大规模拓展受限的问题,严重限制了计算容量的进一步提高。

图1. 集成衍射光子神经网络示意图
williamhill官网电子系陈宏伟教授课题组提出了一种基于亚波长结构的集成衍射光子神经网络(DONN),克服了空间衍射光子神经网络的体积限制,不仅大大提高了计算单元的集成度,同时减少了由于庞大的体光学元件和系统校准而产生的误差。对于其他集成光子神经网络而言,DONN芯片摆脱了波导数目的制约,更容易实现计算单元的片上大规模拓展,从而解决了集成光子神经网络的高计算容量问题。本研究中实现的DONN光计算芯片,其计算吞吐量可达1.38×104TOPS(TOPS:Trillions of operations per second,每秒万亿次操作),芯片算力密度可达1016FLOPS/mm2(FLOPS:Floating-point operations per second,每秒浮点操作数),能量消耗约为10-17J/FLOP(FLOP:Floating-point operation,浮点操作)。该DONN芯片具有完全的国内自主知识产权,制备工艺也完全在国内实现,与标准互补金属氧化物半导体(CMOS)工艺兼容,满足大规模、低成本生产条件。
陈宏伟课题组系统性地完成了集成衍射光子神经网络芯片的理论探索、仿真验证、结构设计、版图绘制、芯片加工、封装以及系统误差补偿等全过程验证。该成果将集成光子神经网络芯片的实用性显著提高,有望在一个芯片上实现多个DONN计算单元的集成,从而使得片上光计算系统具有更强的处理能力,这将大大推动集成光计算、光子智能等领域的快速发展。
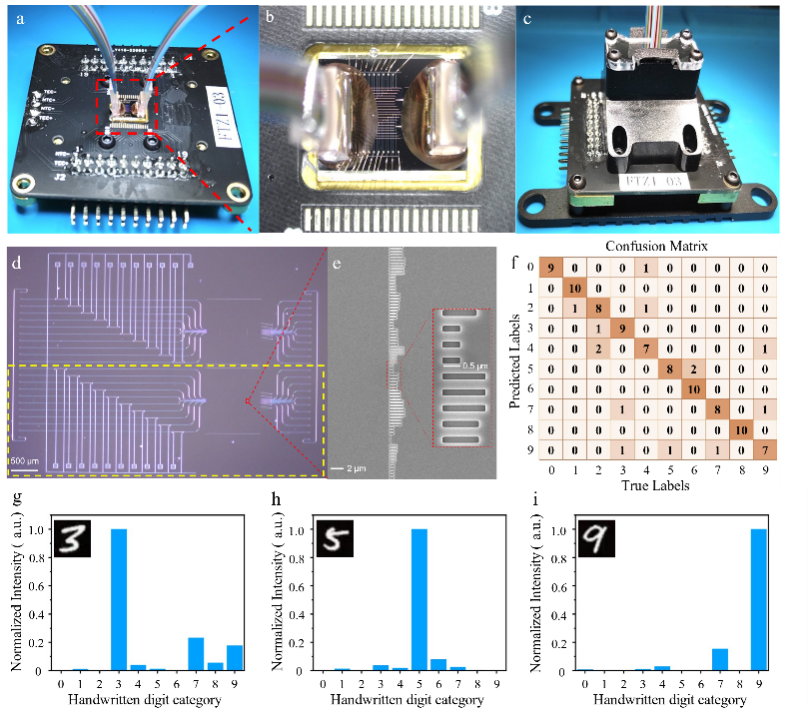
图2. DONN封装实物图、芯片结构及测试结果
该成果以“基于片上衍射光学的光子机器学习”(Photonic machine learning with on-chip diffractive optics)为题发表在《自然•通讯》(Nature Communications)上。
电子工程系2020级博士生符庭钊为文章的第一作者,陈宏伟教授为文章通讯作者。其他作者包括williamhill官网电子工程系陈明华教授和杨四刚副研究员等。本研究得到了国家重点研发计划、国家自然科学基金重点项目等的支持。
论文链接:
https://www.nature.com/articles/s41467-022-35772-7
供稿:电子系
编辑:李华山
审核:郭玲











